Basic Concepts
What is AI?
AI , or Artificial Intelligence, is , as the name suggests, the science and technology that enables machines to simulate human intelligence.
Let’s use an example to illustrate this:
A typical computer program is like a vending machine. You press a specific button (input), and it gives you a specific drink (output). All its behaviors are pre-defined rules by the programmer.
Artificial intelligence programs are more like children learning. You show them many pictures of cats and dogs (data) and tell them which is a cat and which is a dog. After learning, when you show them a picture of a cat they’ve never seen before, they can recognize it. They learn patterns from the data themselves , rather than relying on hard-coded rules.
Therefore, the core of AI is learning from experience and making decisions or predictions based on what it has learned.
The most mainstream and attention-grabbing branch of AI currently is generative artificial intelligence , also known as AIGC (Artificial Intelligence Generated Content) . Unlike traditional AI (primarily used for data analysis, such as facial recognition), its goal is to automatically generate or create various types of digital content using artificial intelligence technology , such as writing articles, reports, translations, and programming.
To better understand AI, let’s first understand some of its common terms.
Model
A model is the core of an AI system ; it is the result of training an algorithm on data . Essentially, a model is a mathematical function that receives input data, performs calculations, and then produces an output.
When we say “calling an AI,” we are actually using that “model.” Model files vary in size, ranging from a few MB to tens of GB.
You can think of an AI model as a “virtual brain .” This brain acquires skills and knowledge through “training” or “learning” on massive amounts of data. When asked a question, it needs to use the knowledge it has acquired to solve the problem.
Large Language Model (LLM)
LLM ( Large Language Model) : A deep learning- based model trained on massive amounts of text data . Its main task is to understand and generate human language. LLMs are representative of the current generative AI trend. Their defining characteristic is ” large ,” reflected in the large amount of training data and the enormous number of model parameters.
It can be viewed as an “expert brain” that has undergone massive training . By learning almost all texts on the internet, it has mastered the grammar, syntax, factual knowledge, and contextual logic of languages, possessing hundreds of billions or even trillions of parameters. And because it has learned everything, it can handle a wide variety of topics and tasks.
Prompt
Prompt: Instructions, questions, or contextual information provided by the user to the AI model . The model generates a corresponding response based on the prompt. The quality of the prompt directly determines the quality of the AI’s answer.
The process of designing and optimizing prompts is known as ” prompt engineering ,” and it is an emerging skill.
The prompts are like ” work orders” given to the AI, this “genius .” The clearer and more specific the order, the higher the quality of the completed work.
For example:
Simple prompt : “What is the capital of France?” -> Model answers: “Paris”.
Complex prompt (role-playing) : “Imagine you are a senior nutritionist. Please design a healthy lunch menu for me (an office worker who sits for long periods) for a week.” -> The model will provide a detailed menu in the voice of a nutritionist.
Token
Token : This is the basic unit of text that the model processes and understands . It is not entirely equivalent to an English word or a Chinese character. Before processing, the model breaks the text down into tokens. Tokens are also the basic unit for billing and measuring the length of text processed by the model.
In English, the word
“unbelievable”can be broken down into three morphemes: “un”, “believe”, and “able”.In Chinese, the phrase “I like programming” can likely be broken down into four word units: “I”, “like”, “enjoy”, and “programming”.
Different models use different word segmentation rules, and the same word may be split into different word units in different models.
Having grasped the basic concepts of AI, let’s now look at Spring AI- related content.
What is Spring AI?
Spring AI is an open-source artificial intelligence application framework built on the Spring ecosystem . Its core goal is to simplify the integration of AI functionality into Java applications , enabling Java developers to efficiently build generative AI applications.
Official Documentation: Introduction :: Spring AI Reference Documentation – Spring Framework
Spring AI provides abstractions that form the foundation for developing AI applications . These abstractions have multiple implementations, allowing for easy component switching with minimal code changes .
Spring AI offers a range of powerful and practical features, making it a fully functional AI application development framework:
1. Unified multi-model support : Supports interaction with numerous mainstream AI model providers, including OpenAI , Microsoft , Amazon , Google , and Anthropic . Whether the model is in the cloud or deployed locally (such as through Ollama), it can be invoked through a consistent interface.
2. Powerful data integration capabilities : This is a major highlight of Spring AI. It has built-in support for vector databases such as Chroma, Pinecone, and Redis.
3. Seamless integration with the Spring ecosystem : As a member of the Spring family, it can naturally work with other well-known projects such as Spring Boot and Spring Data .
4. Simplified development model: Allows AI models to request and execute client-defined functions as needed, thereby accessing real-time information or triggering specific actions.
After understanding the relevant concepts, let’s get hands-on and experience Spring AI.
Quick Start
Environmental requirements
JDK version: JDK 17 or above (JDK 21 recommended). This is mandatory because Spring Boot 3.x itself requires JDK 17+.
Spring Boot version: Spring Boot 3.2 or above , specifically 3.3.3, 3.4.3 or 3.5.0. Just choose a stable latest version of 3.x.
AI Service Credentials: A valid API Key, requiring an account and API Key from an AI service provider (such as OpenAI, DeepSeek, Alibaba Cloud, etc.).
Project creation
Spring AI has designed the spring-ai-openai-spring-boot-starter specifically for OpenAI and compatible API services , for quickly integrating large model language capabilities into Spring Boot applications:
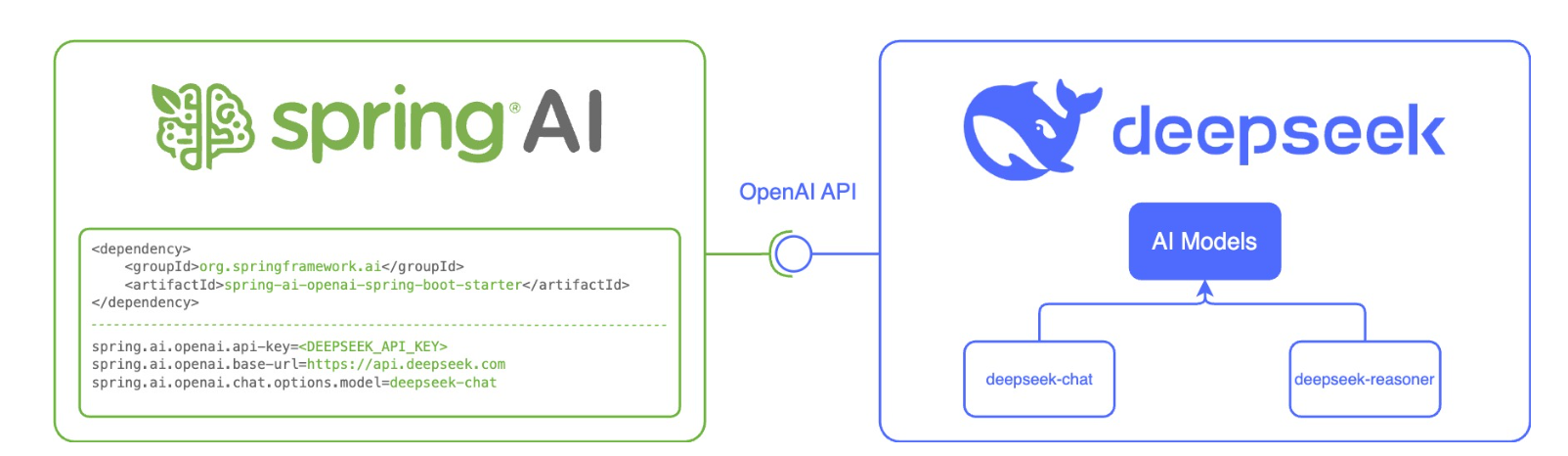
Create a Maven project normally (note the JDK and Spring Boot versions), and add the Spring AI dependency :
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>For dependency version information, please refer to: https://docs.spring.io/spring-ai/reference/getting-started.html
Configure the API key in application.yml :
spring:
ai:
openai:
#DeepSeek
api-key: API Key applied for
base-url: https://api.deepseek.com
chat:
options:
model: deepseek-chat
temperature: 0.7
in:
spring.ai.openai.base-url : The URL to connect to
spring.ai.openai.api-key : The DeepSeek API key you requested.
spring.ai.openai.chat.options.model : The DeepSeek LLM model to use.
`spring.ai.openai.chat.options.temperature` : Controls the randomness and creativity of the text generated by the model: Low temperature (close to 0.0) → conservative, deterministic, predictable; High temperature (close to 2.0) → adventurous, diverse, imaginative. In other words, the lower the temperature value, the more similar the results will be for the same question. Furthermore, it is not recommended to modify both `temperature` and `top_p` in the same completion request , as the interaction between these two settings is difficult to predict.
Configuration options can be found at: https://docs.spring.io/spring-ai/reference/api/chat/deepseek-chat.html
At this point, the project creation and DeepSeek integration are complete . Next, we will write an interface to call the model.
Interface writing
@RestController
@RequestMapping("/deepseek")
public class DeepSeekChatController {
@Autowired
private OpenAiChatModel deepSeekChatModel;
@GetMapping("/chat")
public String generate(String message) {
return deepSeekChatModel.call(message);
}
}
Run and access 127.0.0.1:8080/deepseek/chat?message=who are you to test.
As described above, we completed the interaction with the model through ChatModel.
In the Spring AI framework, ChatModel and ChatClient are the two core interfaces for building conversational AI applications. We will now examine these two interfaces separately.
Core Interface
ChatModel
ChatMode communicates directly with the underlying AI models (such as GPT-4, Claude, etc.) to handle raw requests and responses.
Therefore, ChatModel is more low-level and more flexible in use.
@Service
public class ChatService {
@Autowired
private ChatModel chatModel; // For example, OpenAiChatModel
public String askQuestion(String question) {
// 1. Construct the message
UserMessage userMessage = new UserMessage(question);
// 2. Create the Prompt
Prompt prompt = new Prompt(List.of(userMessage));
// 3. Call and get the complete response
ChatResponse response = chatModel.call(prompt);
// 4. Extract the content from the response
return response.getResult().getOutput().getContent();
}
}
ChatClient
ChatClient provides a smooth API layer on top of ChatModel , simplifying common usage patterns.
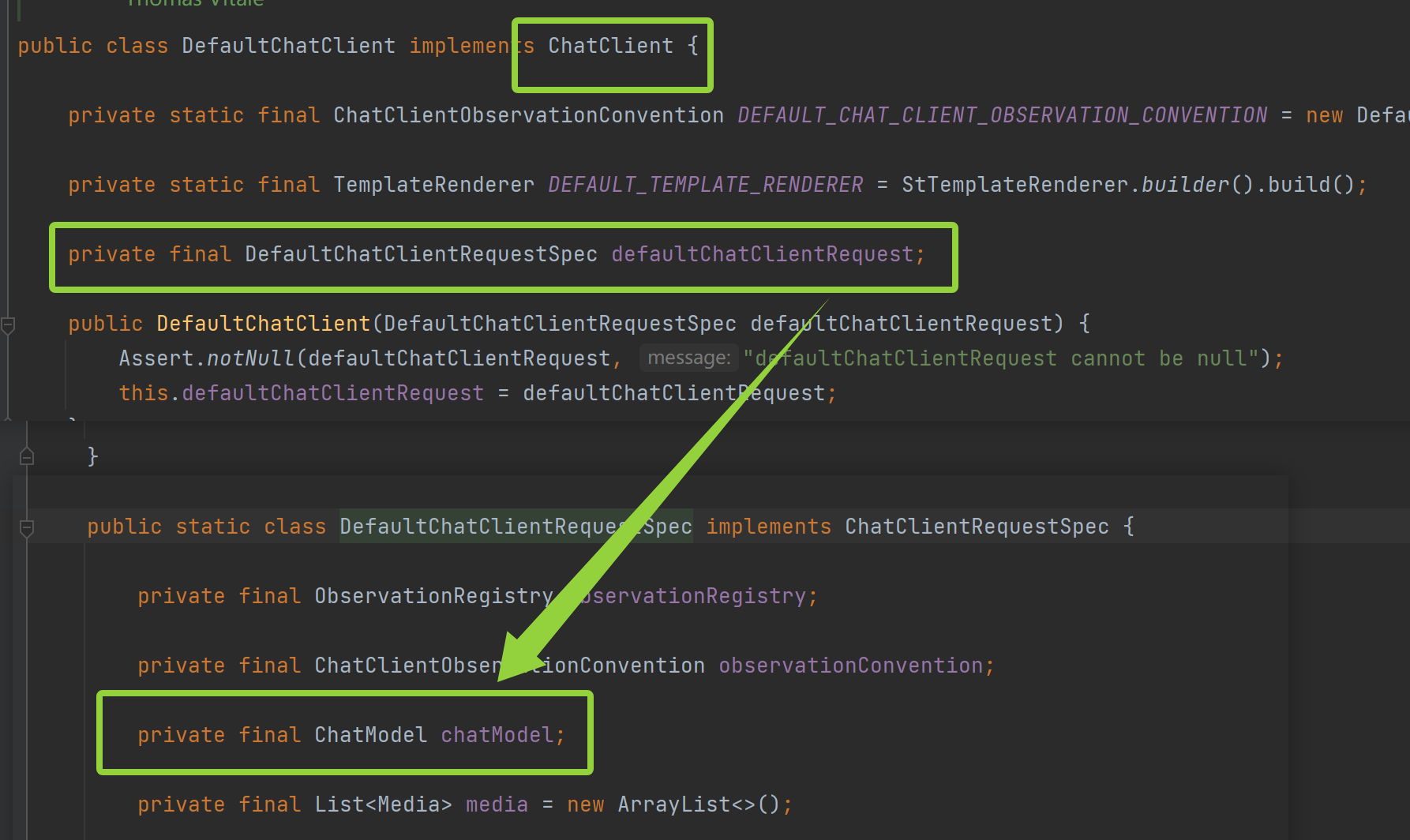
In other words, ChatClient is a wrapper around ChatMode .
Therefore, ChatClient is more advanced and also more concise.
@Service
public class ChatService {
@Autowired
private ChatClient chatClient;
public String askQuestion(String question) {
// Get it done in one line
return chatClient.call(question);
}
}
As you can see, ChatClient is simpler and more intuitive to use.
Comparison between ChatMode and ChatClient :
| Dimension | ChatModel | ChatClient |
|---|---|---|
| Abstraction level | The bottom layer, close to the original model | High-level, business-oriented |
| Return value | ChatResponse (a complete response object containing rich metadata) | ChatResponse (plain text that directly retrieves content) or streaming response |
| How to use | The Prompt object needs to be constructed manually. | Provides a streaming builder pattern |
| Control granularity | Fine control | quick and easy |
Message Type
In Spring AI, all message types implement the `org.springframework.ai.chat.messages.Message` interface, and the messages in the system are designed to simulate different participants in a multi-turn dialogue.
| Message Type | Corresponding role | core role |
|---|---|---|
| SystemMessage | System/Director | Define the AI’s background, role, behavior, and response style. This is typically provided at the beginning of the conversation, setting the tone for the entire session. |
| UserMessage | User/Questioner | Representing the human side in human-computer interaction, it is the driving force behind the dialogue. |
| AssistantMessage | Assistant/AI itself | This represents the AI’s responses in previous rounds. It ensures the continuity of multi-round dialogue. |
| FunctionMessage | Functions/Tools | This represents additional information or operational results obtained by AI through function calls. |
| ToolMessage | tool | It has the same function as ToolMessage and is an alias for ToolMessage. |
| MediaMessage | multimedia | This represents message data of other types besides text, such as images. |
Among them, the most commonly used are SystemMessage, UserMessage, and AssistantMessage.
SystemMessage
SystemMessage is typically used to set the AI assistant’s identity, personality, behavioral guidelines, and dialogue rules. It usually appears at the beginning of the conversation, setting the tone for the entire dialogue.
For example, we can pre-set its roles :
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultSystem("Your name is Xiaoxiaoyu, a professional intelligent Q&A AI assistant, proficient in Java and Python, answering questions with a friendly attitude")
.build();
}
@GetMapping("/call")
public String generation(String userInput) {
return this.chatClient.prompt()
.user(userInput) // User input.call
() // Call the API
.content(); // Return the response
}
}
In ChatClient , the default system message for the AI model is set via defaultSystem . The system messages set through chained calls to ChatClient.Builder serve as the “initial instructions” for each conversation , being injected into the context of each conversation to guide the AI’s response style or identity setting.
At this point, we access the interface and ask for its identity again.
UserMessage
UserMessage represents the specific question or instruction we are asking. The “Who are you?” input above is a UserMessage.
AssistantMessage
AssistentMessage : This is the response provided by the AI model.
AssistantMessage is key to enabling coherent multi-turn conversations . Each time the AI responds, this response can be saved as an AssistantMessage and sent to the AI as part of the historical context on the next request.
Output format
Structured output
To receive structured output from an LLM , Spring AI supports changing the return type of the ChatModel/ChatClient methods from Spring to other types.
The model output is converted into a custom entity using the entity() method.
For example:
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.build();
}
@GetMapping("/entity")
public String entity(String userInput) {
Recipe entity = this.chatClient.prompt()
.user(String.format("Please help me generate a recipe for %s", userInput))
.call()
.entity(Recipe.class);
return entity.toString();
}
record Recipe(String dis, List<String> ingredients) {}
}
Streaming output
First, let’s compare and contrast what streaming output is:
Traditional output (non-streaming ): Returns the entire output all at once only after all data has been generated , resulting in a long wait for the user → then suddenly the complete answer is displayed. It’s like sending a regular letter ; you write all the content before sending it, and the recipient receives the entire letter at once.
Streaming output : Generates and returns results simultaneously , pushing partial results immediately and starting to display almost instantly → growing word by word. Like making a phone call , you can hear the other person speaking at the same time.
Streaming output process:
User question: “Please write a short essay about spring.”
AI model generation process:
“Spring”… (Return Now)
Spring is here… (Continue back)
“Spring is here, and all things are coming back to life”… (Continue to return)
Until a complete answer is generated, the SSE protocol is followed.
Spring AI primarily achieves streaming output through reactive programming , using the `stream()` method to generate a `Flux<String> ` stream.
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.build();
}
@GetMapping(value = "/stream", produces = "text/html;charset=utf-8")
public Flux<String> stream(String userInput) {
return this.chatClient.prompt()
.user(userInput)
.stream()
.content();
}
record Recipe(String dis, List<String> ingredients) {}
}
However, let’s consider this question: Since the HTTP protocol itself is designed as a stateless request-response model, which means that strictly speaking, it is impossible for the server to actively push messages to the client, how can we achieve streaming responses from the server?
We can achieve streaming using SSE (Server-Sent Events) , which allows the server to proactively push data streams to the browser.
SSE Protocol Introduction
SSE is a lightweight real-time communication protocol based on HTTP . Browsers receive and process these real-time events through the built-in EventSource API.
The server declares to the client that the next message to be sent is a streaming message.
At this point, the client will not close the connection and will wait indefinitely for the server to send a new data stream.
SSE core features:
1. One-way communication : Data can only be pushed from the server to the client . The client cannot send data to the server through this connection (except for the initial connection establishment request).
2. Based on HTTP/HTTPS : SSE uses the standard HTTP protocol, which means it can easily bypass most firewalls and proxy servers without special configuration.
3. Persistent connection : The client initiates a normal HTTP request, but the server keeps the connection open instead of closing it after sending a response.
4. Text data stream : The server continuously sends a stream of text data that follows a specific format to the client through this persistent connection.
5. Automatic reconnection : The SSE protocol has a built-in reconnection mechanism. If the connection is unexpectedly lost, the browser will automatically attempt to reconnect to the server.
SSE Data Format
When a server sends SSE data to a browser, it needs to set the required HTTP header information.
Content-Type: text/event-stream;charset=utf-8
Connection: keep-aliveThe entire data stream consists of a series of messages. Each message comprises one or more lines of text , each line beginning with a field name , followed by a colon and a space, then the field value. Each message ends with a blank line (i.e., two consecutive newline characters \n\n).
Each line format: [field]: value\n
Common values for the field include: data, event, id, and retry.
data
`data` : The message body, the most important field, carries the actual content of the message . If a message contains multiple data lines, the client will \nconnect them with newline characters (“) to form a complete data string. It can be used to transmit any text data such as JSON strings, plain text, and XML.
Example:
data: This is a simple message\n\n
data: !\n\n
data: Hello\n
data: World\n
event
`event` : Event type, used to specify the custom type of the message. If this field is provided, the client will trigger a listener for that specific event name; otherwise, a general onmessage event will be triggered, which can be used to classify and process different types of messages.
Example:
event: userJoined
data: Alice
id
`id` : Event ID, used to assign a unique ID (string) to the message. If the connection is interrupted, the last received ID will be automatically sent in the HTTP request header when the client reconnects. This can be used to implement idempotency and resumable interrupted downloads . Last-Event-ID
Example:
id: msg-123data: This is an important message
retry
`retry` : Reconnection time. This indicates the number of milliseconds the browser should wait before retrying the connection after it has been lost . Since this is not a mandatory command , the browser may ignore it. It is used to prevent the client from retrying too frequently when the server experiences a failure.
Example: Tell the browser to wait 10 seconds before trying to reconnect if the connection fails.
retry: 10000
Let’s look at a simple example of the use of the SSE protocol.
SSE Usage Examples
Backend API:
@Slf4j
@RequestMapping("/sse")
@RestController
public class SseController {
@RequestMapping("/end")
public void end(HttpServletResponse response) throws IOException, InterruptedException {
log.info("Request initiated: event");
response.setContentType("text/event-stream;charset=utf-8");
PrintWriter writer = response.getWriter();
for (int i = 0; i < 10; i++) {
// Event foo Event
String s = "event: foo\n";
s += "data: " + new Date() + "\n\n";
writer.write(s);
writer.flush();
Thread.sleep(1000L);
}
// Define the end event, indicating the end of the current stream
writer.write("event: end\ndata: EOF\n\n");
writer.flush();
}
}
Front-end implementation:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>SSE</title>
</head>
<body>
<div id="sse"></div>
<script>
let eventSource = new EventSource("/sse/end");
eventSource.addEventListener("foo", function(event) {
console.log(event);
document.getElementById("sse").innerHTML = event.data;
});
eventSource.addEventListener("end", function(event) {
console.log("Connection closed")
eventSource.close();
});
</script>
</body>
</html>
Run the program and observe the logs printed in the console.
You can see that the message was successfully transmitted and the connection was closed after the message transmission was complete.
In Spring, the SSE protocol can be elegantly implemented using WebFlux , which is the Flux we used earlier . It is the core component of WebFlux . Let’s look at the usage and common operations of Flux.
Flux
Flux workflow: Create → Transform → Filter → Consume
Create Flux :
import reactor.core.publisher.Flux;
// 1.1 Create Flux from a fixed value
<String> fixedFlux = Flux.just("Hello", "World", "!");
// 1.2 Create a List from a collection
<String> list = Arrays.asList("A", "B", "C");
Flux<String> fromCollection = Flux.fromIterable(list);
// 1.3 Create a range of values
Flux<Integer> rangeFlux = Flux.range(1, 5); // 1,2,3,4,5
// 1.4 Dynamically generate
Flux<Long> intervalFlux = Flux.interval(Duration.ofSeconds(1)).take(5);
// 1.5 Create
a Flux from an array<String> arrayFlux = Flux.fromArray(new String[]{"X", "Y", "Z"}));
// 1.6 Create an empty stream
Flux<String> emptyFlux = Flux.empty();
// 1.7 Create from a Future (adapting to traditional asynchronous APIs):
`CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Result");`
`Flux<String> futureFlux = Flux.fromFuture(future);`
Conversion operation :
// 2.1 map - One-to-one conversion
Flux<String> original = Flux.just("apple", "banana", "cherry");
Flux<String> uppercased = original.map(String::toUpperCase); // APPLE, BANANA, CHERRY
// 2.2 flatMap - One-to-many conversion (asynchronous flattening)
Flux<String> words = Flux.just("hello world", "spring ai");
Flux<String> splitWords = words.flatMap(word ->
Flux.fromArray(word.split(" "))
);
// 2.3 cast - Type conversion
Flux<Object> objects = Flux.just("text1", "text2");
Flux<String> strings = objects.cast(String.class);
// 2.4 scan - Cumulative calculation
Flux<Integer> numbers = Flux.range(1, 4);
Flux<Integer> cumulativeSum = numbers.scan((acc, current) -> acc + current); // 1,3,6,10
Filtering operation:
// 3.1 filter - Conditional filtering
Flux<Integer> allNumbers = Flux.range(1, 10);
Flux<Integer> evenNumbers = allNumbers.filter(n -> n % 2 == 0); // 2,4,6,8,10
// 3.2 distinct - Removing duplicates
Flux<String> withDuplicates = Flux.just("A", "B", "A", "C");
Flux<String> uniqueItems = withDuplicates.distinct()); // A,B,C
// 3.3 take - Taking the first N
Fluxes Flux<String> limited = original.take(2); // apple, banana
// 3.4 skip - Skipping the first N
Fluxes Flux<String> skipped = original.skip(1); // banana, cherry
// 3.5 takeWhile / skipWhile - Conditional taking/skipping
Flux<Integer> sequence = Flux.range(1, 100);
Flux<Integer> firstPart = sequence.takeWhile(n -> n < 10); // 1,2,3,...,9
// 3.6 sample - sampling (periodically taking the latest element)
Flux<Long> sampled = Flux.interval(Duration.ofMillis(100)))
.sample(Duration.ofSeconds(1)))
.take(3); // Sample every 1 second, for a total of 3 times
Consumption Operation :
// 4.1 subscribe - The most basic consumption method
Flux<String> data = Flux.just("one", "two", "three");
data.subscribe(
item -> System.out.println("Received: " + item),
error -> System.err.println("Error: " + error)),
,
() -> System.out.println("Completed!"))
);
// 4.2 collectList - Collect all elements into a List
Mono<List<String>> listMono = data.collectList());
// 4.3 blockFirst / blockLast - Blocking fetching (for testing purposes only)
// String first = data.blockFirst();
// 4.4 reduce - Reduction operation
Mono<Integer> sum = numbers.reduce(0, Integer::sum));
// 4.5 count - Counting
Mono<Long> count = data.count();
// 4.6 hasElement - Check if there is an element
Mono<Boolean> hasData = data.hasElements();
// 4.7 then - Ignore elements, only trigger
Mono<Void> completionSignal = data.then();
Advisors
Advisors are an interceptor mechanism in Spring AI that allows us to inject custom logic into specific nodes of the AI call chain.
Advisors intervened at two key moments:
Before Call : Executed before the request is sent to the AI model , primarily used to modify prompt words.
After Call: Executed after receiving the AI response but before returning it to the client.
Its execution process is as follows:
User input → Advisor1.before() → Advisor2.before() → AI model call → Advisor2.after() → Advisor1.after() → Final response
Spring AI includes several built-in Advisors , such as SimpleLoggerAdvisor , whose main function is logging. Simply adding it to the Advisor chain will automatically record the Advisor’s chat requests and responses.
@RequestMapping("/chat")
@RestController
public class ChatClientController {
private ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultSystem("Your name is Xiaoxiaoyu, a professional intelligent Q&A AI assistant, proficient in Java and Python, answering questions with a friendly attitude")
.build();
}
@GetMapping("/advisor")
public String advisor(String userInput) {
return this.chatClient.prompt()
.advisors(new SimpleLoggerAdvisor())
.user(userInput)
.call()
.content();
}
record Recipe(String dis, List<String> ingredients) {}
}
We configured the log level to debug for observation:
logging:
level:
org.springframework.ai.chat.client.advisor: debugObserve the printed log content