Brief
1) Basic Network Model
- Multilayer Perceptron (MLP): Fully connected layers stacked, with no spatial structure preserved.
- Convolutional Neural Networks (CNNs): Contains convolutional layers and pooling layers, primarily for image/spatial data.
- Classic subtypes: LeNet, AlexNet, VGG, GoogLeNet, ResNet
- Recurrent Neural Networks (RNNs): Contain recurrent layers, primarily for sequential data.
- Classic subtypes: LSTM, GRU
- Transformer: Based on self-attention mechanism, adaptable to sequence/image/multimodal data.
- Classic subtypes: BERT, GPT, Vision Transformer (ViT)
2) Model Core Settings (Component Selection)
- Network layers: Convolutional layers, fully connected layers, recurrent layers, attention layers, pooling layers
- Activation functions: ReLU, Sigmoid, Tanh, GELU
- Optimizers: SGD, Adam, RMSProp, AdamW
- Loss functions: Cross-entropy loss, MSE, MAE, Triplet Loss
- Regularization: Dropout, L1/L2 regularization, BatchNorm, LayerNorm
- Data processing: normalization, enhancement, padding, truncation, tokenization (NLP), tokenization (multimodal).
I. A single neuron
1) Structure
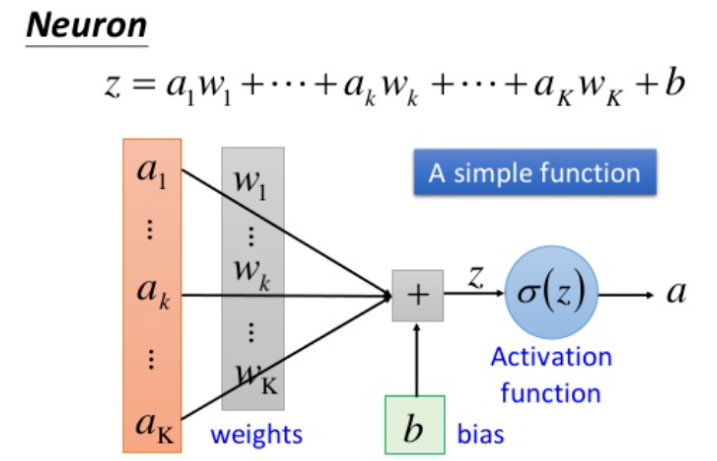
- Input : Receive external signals, represented by a vector (x = [x_1, x_2, …, x_n]), with each input corresponding to a weight.
- Weights and biases :
- Weights w = [w1, w2, …, wn] w=[w_1,w_2,…,w_n] w=[w1,w2,…,wn]: Measure the importance of each input (positive numbers enhance the signal, negative numbers suppress the signal);
- Bias b: Adjusts the activation threshold of neurons, controlling the sensitivity of neuronal responses.
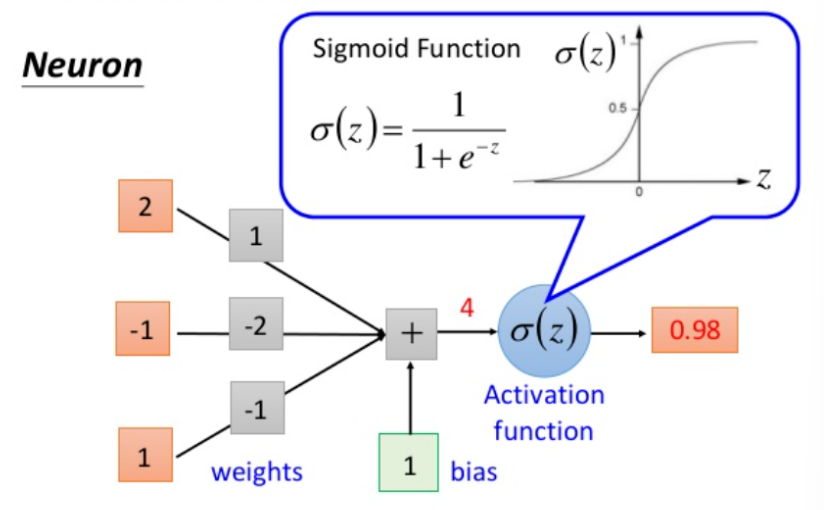
- Activation function : Perform a nonlinear transformation on the weighted sum z = ∑ ( wixi ) + bz = \sum(w_i x_i) + b z=∑(wixi)+b to output the final signal ( a = f(z) ) (such as ReLU, Sigmoid).
2) Significance
- Basic computing unit : Learns simple features of input data (such as edges and keywords) through “weighted summation + nonlinear transformation”.
- Network foundation : The capabilities of a single neuron are limited (it can only fit simple nonlinear relationships), but when a large number of neurons are stacked in layers (forming a multi-layer network), low-order features can be combined to form high-order abstract features (such as “image category” and “text semantics”), providing a foundation for neural networks to process complex tasks.
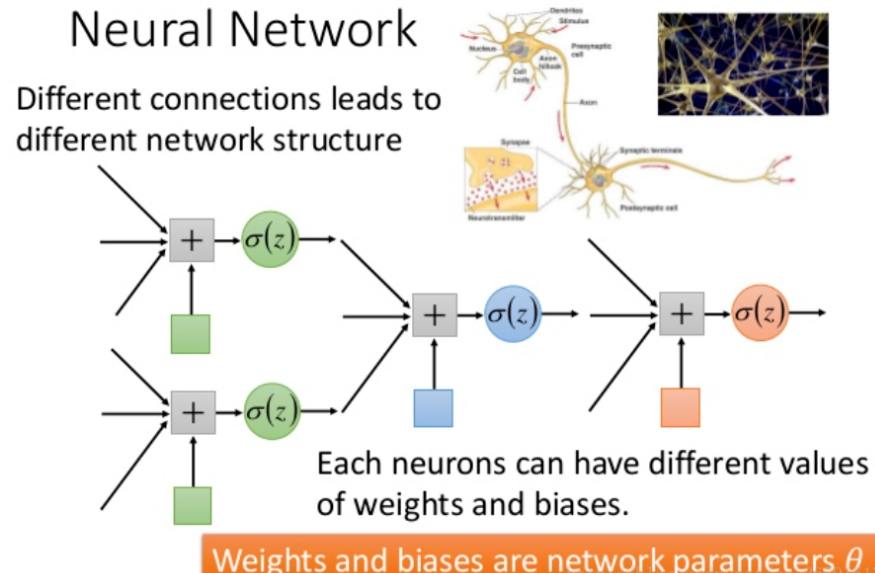
II. Basic Network Model
1. Multilayer Perceptron (MLP)
- Key features: Stacked fully connected layers, input is a flattened vector, no spatial or sequential structure is preserved.
- Classic subtype:
- Autoencoder : An encoder-decoder structure used for unsupervised feature learning (dimensionality reduction, noise reduction).
- Variational autoencoder (VAE) : A generative model that introduces probability distribution assumptions to generate new samples.
- GAN basic structure : Both the generator and discriminator are MLP architectures, and generative tasks are achieved through adversarial training.
2. Convolutional Neural Network (CNN)
- Key features : Contains convolutional layers (for extracting local features) and pooling layers (for dimensionality reduction), specifically designed for image/spatial data.
- Classic Subtypes : Core Model Innovations and Application Scenarios LeNet first established the “convolution + pooling + fully connected” framework for handwritten digit recognition. AlexNet introduced ReLU and Dropout, supporting GPU parallelism for large-scale image classification. VGG’s 3×3 convolution kernel stacking enhances performance through depth. Image Feature Extraction: GoogLeNet’s Inception module extracts multi-scale features in parallel for efficient feature learning. ResNet’s residual connections solve the gradient vanishing problem in deep networks. Ultra-deep network training (e.g., 152 layers): DenseNet’s dense connections enhance feature reuse and reduce parameters. Lightweight Scenarios: MobileNet’s depthwise separable convolutions are suitable for mobile devices and mobile image tasks.
3. Recurrent Neural Network (RNN)
- Key features : Includes a recurrent layer, can process sequential data (such as text and speech), and preserves temporal dependencies.
- Classic subtype :
- LSTM/GRU : Solves the vanishing gradient problem in long sequences and is suitable for long text and speech modeling.
- Bidirectional RNN (Bi-RNN) : It utilizes both forward and backward sequence information to improve semantic understanding.
- Seq2Seq : An encoder-decoder architecture used for sequence transformation tasks such as machine translation and text summarization.
4. Transformer
- Key features : Based on the self-attention mechanism, it processes sequences in parallel, breaking through the temporal dependency limitation of RNNs.
- Classic Subtype : Core Model Innovations and Application Scenarios BERT bidirectional Transformer pre-training, adaptable to NLP tasks such as text classification and question answering; GPT autoregressive generative Transformer, adept at text generation; ViT segments images into “patches” and uses Transformer for image classification; Swing Transformer sliding window attention, adaptable to high-resolution image object detection and semantic segmentation; T5 unifies NLP tasks as “text-to-text” format general NLP tasks.
III. Extended Network Model
1. Cross-modal and fusion models
- Core logic : Processing the interaction and fusion of multiple types of data such as text, images, and voice.
- Representative model :
- CLIP : Jointly trains text and image encoders to achieve cross-modal retrieval.
- ViLBERT : A two-stream Transformer that processes images and text separately, fused through cross-modal attention.
- Whisper : A multilingual speech recognition model based on Transformer.
2. Graph Neural Networks (GNNs)
- Core logic : Process graph-structured data (such as social networks and molecular structures) and learn features through nodes and adjacency relationships.
- Representative model :
- GCN : Extends convolution to graph structures, aggregating node features through adjacency matrices.
- GAT : Uses an attention mechanism to dynamically adjust the weights of adjacent nodes, improving flexibility.
- Graph Transformer : Combines self-attention mechanism to break through the fixed adjacency dependency of GCN.
3. Reinforce learning-related networks
- Core logic : Used for decision-making tasks, it learns the optimal strategy through interaction with the environment.
- Representative model :
- DQN : Combining CNN and Q-learning, it is used for discrete action spaces (such as game AI).
- Policy Gradient : Directly optimizes the policy function, suitable for continuous action spaces (such as robot control).
- Actor-Critic : Combines the policy network (Actor) and the value network (Critic) to balance exploration and exploitation.
Neural network core components
I. Network Layer (Basic Building Block)
- Core layer
- Convolutional layers
Conv2d: Extract local features by sliding convolution kernels (like / in CNNsConv3d, suitable for images/videos). - Fully connected layer : Connects input and output in all dimensions (
Linear), used for feature mapping to the output space (such as classification results). - Recurrent layer : processes sequential data (
RNN/LSTM/GRU), preserving temporal dependencies. - Attention layer : Dynamically assigns weights to the input sequence (such as self-attention, cross-attention), adapting to Transformer.
- Pooling layer : Reduces feature dimension (
MaxPooling/AvgPooling) and enhances robustness.
- Convolutional layers
- Extension layer
- Normalization layer : Stabilize training (
BatchNorm/LayerNorm/InstanceNorm, adapt batch/layer/single sample normalization according to different scenarios). - Dropout layer : Randomly deactivates neurons (
Dropout/DropPathto prevent overfitting). - Embedding layer : Maps discrete values to low-dimensional vectors (
Embeddingapplicable to word vectors in NLP and ID mapping in recommender systems). - Graph convolutional layers : process graph-structured data (
GCNConv/GATConv, aggregate nodes and adjacency features). - Transposed convolutional layer : upsampled features (
ConvTranspose2dused for resolution restoration in image generation and semantic segmentation).
- Normalization layer : Stabilize training (
II. Activation Function (Introducing Nonlinearity)
- core function
- ReLU : f(x) = max(0,x), solves the gradient vanishing problem and is computationally efficient (most widely used).
- Sigmoid : f(x) = 1 / (1 + e − x) f(x) = 1/(1+e^{-x}) f(x)=1/(1+e−x), the output is mapped to (0,1), suitable for binary classification probability output.
- Tanh : f(x) = (ex − e − x) / (ex + e − x) f(x) = (e^x – e^{-x})/(e^x + e^{-x}) f(x)=(ex−e−x)/(ex+e−x), the output is mapped to (-1,1), which is more symmetric than Sigmoid.
- GELU : f(x) = x ⋅ Φ(x) f(x) = x \cdot \Phi(x) f(x)=x⋅Φ(x) (Gaussian error linear unit), smooth nonlinearity, adapted to Transformer.
- extension functions
- LeakyReLU : f(x) = max(0.01x,x) f(x) = max(0.01x,x) solves the “dead neuron” problem of ReLU.
- Swish : f(x) = x ⋅ Sigmoid (βx) f(x) = x \cdot \text{Sigmoid}(\beta x) f(x)=x⋅Sigmoid(βx), a self-gated mechanism that performs well in deep networks.
- Softmax : f(xi) = exi / ∑ exjf(x_i) = e^{x_i}/\sum e^{x_j} f(xi)=exi/∑exj, normalizes the output into a probability distribution, suitable for multi-class classification.
III. Optimizer (Parameter Update Strategy)
- Core Optimizer
- SGD : Stochastic Gradient Descent, a basic optimizer that can
momentumbe accelerated to convergence by adding momentum ( ). - Adam : Combining momentum and adaptive learning rate (
beta1/beta2controlling momentum and second moment), it is suitable for most scenarios. - RMSProp : Adaptively adjusts the learning rate (decaying the squared gradient) to alleviate Adam’s oscillation problem.
- AdamW : Adam+ weight decay, resulting in more stable regularization.
- SGD : Stochastic Gradient Descent, a basic optimizer that can
- Extended optimizer
- Adagrad : Assigns a larger learning rate to sparse features, suitable for sparse data such as text.
- Nadam : Adam + Nesterov momentum, converges faster.
- LAMB : Adapted for large batch training, supports adaptive learning rate scaling.
IV. Loss Function (Measures the difference between prediction and actual value)
- Core loss
- Cross-entropy loss : suitable for classification tasks (
CrossEntropyLossincluding Softmax + negative log-likelihood). - MSE (Mean Squared Error) : Loss = ∑ ( y − y ^ ) 2 \text{Loss} = \sum (y-\hat{y})^2 Loss=∑(y−y^)2, applicable to regression tasks.
- MAE (Mean Absolute Error) : Loss = ∑ ∣ y − y ^ ∣ \text{Loss} = \sum |y-\hat{y}| Loss=∑∣y−y^∣, stronger resistance to outliers than MSE.
- Triplet Loss : Optimizes by using a triplet of “anchor point-positive example-negative example” to bring similar examples closer together and separate dissimilar examples (suitable for face recognition and embedding learning).
- Cross-entropy loss : suitable for classification tasks (
- Extended loss
- Huber Loss : Combining MSE and MAE (using MSE for small errors and MAE for large errors) to balance robustness and gradient stability.
- Dice Loss : Based on Intersection over Union (IoU), it is suitable for imbalanced tasks (such as medical image segmentation).
- KL divergence : measures the difference between two probability distributions (applicable to generative models, such as the regularization term of VAE).
- CTC Loss : Handles the alignment of variable-length sequences (such as the input-output length mismatch problem in speech recognition and OCR).
V. Regularization (to prevent overfitting)
- Core Methods
- Dropout : Randomly deactivates some neurons during training to reduce network dependency.
- L1/L2 regularization : Adds a penalty of the absolute value (L1) or square (L2) of the weights to the loss to limit the size of the weights.
- BatchNorm/LayerNorm : indirectly enhances generalization ability by normalizing and stabilizing the training distribution.
- Extension Methods
- Early Stopping : Monitor validation set performance and terminate training early to avoid overfitting.
- Data augmentation : generating diverse samples through rotation, cropping, etc. (essentially expanding the dataset and reducing overfitting).
- Weight Decay : Weights are decayed proportionally during training (more direct than L2 regularization).
- Knowledge Distillation : Using a large model to guide the training of a small model, thereby improving generalization ability.
VI. Data Processing (Input Preprocessing)
- Core processing
- Normalization : Maps data to a fixed range (such as [0,1] or mean 0, variance 1), accelerating convergence.
- Enhancements : Images (rotation, cropping, adding noise), text (synonym replacement, back translation), etc., to increase data diversity.
- Padding/Truncation : Uniform sequence length (e.g., text padding to a fixed length).
- Tokenization : Text is split into words/sub-words (e.g., NLP
word2vec, BPE; multimodal image patch segmentation).
- Extended processing
- Feature selection : retain important features (such as removing redundant dimensions and reducing noise).
- Dimensionality reduction : Use techniques such as PCA and t-SNE to reduce feature dimensions (suitable for high-dimensional data preprocessing).
- Denoising : Images (Gaussian filtering), speech (spectral subtraction), etc., to improve the quality of input data.
- Format conversion : Converting raw data into a format that the model can accept (such as converting images to Tensors, or text to ID sequences).
Model training process
1. Data preparation:
- Training Set :
- Analogy : Students’ textbooks and homework .
- Function : The model (student) primarily learns from this data to acquire knowledge (such as recognizing features in images). This is the main basis for the model’s learning.
- Validation Set :
- Analogy : A mock exam paper. The questions are ones that students haven’t done before, but the question types and difficulty are similar to the textbook (training set).
- Purpose : During training, it is used periodically to test the model’s learning performance. Its key function is to prevent students from “memorizing” the textbook (i.e., to prevent the model from “overfitting”). If a student scores high on the exam but low on mock exams, it indicates that they may have only memorized the answers without truly understanding the material.
- Test Set :
- Analogy : The final college entrance examination . This is completely confidential; neither students nor teachers have ever seen it.
- Purpose : After the model training is complete, it is used for a final, impartial evaluation to measure the model’s generalization ability in the real world. Note: The test set can only be used once at the end and cannot be used to guide training or parameter tuning.
2. Model Building: Creating a “Learning Machine”
- Analogy : Based on the student’s situation (problem type), develop a learning method or problem-solving approach .
- Purpose : This is the core you will be training. For image recognition, we typically use CNNs (Convolutional Neural Networks); for natural language processing, we might use RNNs or Transformers.
- How to do it : You don’t need to invent from scratch. You can use the “building blocks” (such as convolutional layers and fully connected layers) provided by frameworks such as PyTorch or TensorFlow to build a model structure that suits your task.
3. Training process: Students begin learning
This is usually referred to as the training loop .
- Feeding data : Take a batch of data (e.g., 128 images) from the training set and input it into the model.
- Model prediction : The model makes predictions for these 128 images based on the “knowledge” (weights) it has learned so far.
- Error calculation : The difference between the model’s predicted result and the true label (e.g., the image actually shows the number “5”) is calculated using the loss function . This difference is the loss value .
- Backpropagation and update : This is a crucial step in the model’s “learning.” The computer automatically identifies which “weights” in the model are causing the error and, based on the optimizer’s rules (such as gradient descent), subtly adjusts these weights in the hope of making more accurate predictions next time.
- Repeat : Continuously repeat steps 1-4 until all data in the training set has been learned once (this is called one Epoch ). Then start from the beginning again and perform the second, third and so on Epochs until the model converges.
4. Verification process: Conduct mock exams regularly.
- When to do it : Usually after each epoch , or after a certain number of training steps.
- How to do it : Input all the data from the validation set into the model, and calculate the model’s loss and accuracy on the validation set .
- Why it’s important :
- Preventing overfitting : If the model’s accuracy on the training set is getting higher and higher, but its accuracy on the validation set is starting to drop, it means that the model is starting to “memorize” the training data (overfitting) and its ability to process new data is getting worse.
- Judging the training effect : The metrics of the validation set are an important basis for judging whether the model has “learned well”.
5. Record optimal weights: Save students’ “peak performance”
- When to record : After each validation, if the model achieves its best performance on the validation set for a key metric (such as accuracy) since training began , all the model’s “weights” should be saved immediately.
- Why record these parameters ? The training process is volatile; the model’s state doesn’t always improve. Recording the optimal weights ensures that at the end of training, you have a “peak” model, rather than a final model that may have started overfitting or whose performance is declining. This is similar to capturing a student’s best moment during exam preparation as a final reference.
6. Parameter Adjustment: Adjust learning methods based on exam results.
This is an iterative optimization process, and it is also the key to distinguishing novices from experts.
- When to adjust : When you find that the training and validation results are not ideal.
- Adjust common parameters :
- Learning rate : This is the most important parameter.
- Analogy : The pace of a student’s learning .
- Parameter tuning strategy : If the learning rate is too high, the model may oscillate around the optimal solution and become unstable; if it is too low, the model will learn very slowly and require a very long training time to converge. It is usually necessary to start with a small range (such as 0.001).
- Model structure :
- Analogy : Adjust your learning methods , such as changing from rote memorization to understanding-based memorization.
- Parameter tuning strategies : If the model is too simple (e.g., too few layers), it may not learn enough knowledge (underfitting), resulting in low accuracy on both the training and validation sets. In this case, you can try increasing the number of network layers or the number of neurons per layer. Conversely, if the model is too complex, it is prone to overfitting.
- Batch Size :
- Analogy : The number of questions a student does each time .
- Parameter tuning strategies : Larger batch sizes result in more stable training, but place higher demands on computer memory/GPU memory. Smaller batch sizes may lead to faster training, but the process may be more volatile.
- Optimizer :
- Analogy : Different learning strategies , such as SGD (Stochastic Gradient Descent), Adam, etc.
- Parameter tuning strategy : Adam is usually the first choice for beginners because it converges quickly and is robust.
- Learning rate : This is the most important parameter.